

テキストマイニング・データマイニング
データマイニング/テキストマイニング
特許分析の基本は、個々の特許文献を読み込んで把握することですが、多大な労力がかかります。全体俯瞰をすばやく行う場合には、マイニングが便利です。弊社では、2000年前後からSOMや多変量分析をはじめとした各種のアルゴリズムのデータマイニング手法を特許データの処理に導入しました。
特許マップとマイニングの相違点
特許マップもマイニングもデータの可視化である点では同様ですが、特許マップでは軸や場が人間の認知する属性で制御されて決められているのに対して、多くのマイニングでの軸や場は、データの性質を所定の多次元のアルゴリズムで分析した結果を二次元にそのまま展開したものであり、意味を持ちません。そのため、マイニングの結果は、全体像として把握するよりも、むしろクラスタ内の想定できない何らかの新しい発見に強みがあります。また、特許マップで作成するクラスタ(分類)は、人が認知した属性上のデータの集まりであるのに対して、マイニングで言うクラスタは、データの類似性を示しており、両社は似ている結果を導き出すことはありますが、利用方法を分ける必要があります。
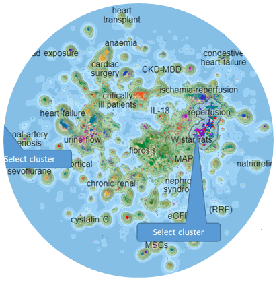

マイニングの手法と主な種類
語と語の関係性を分析する
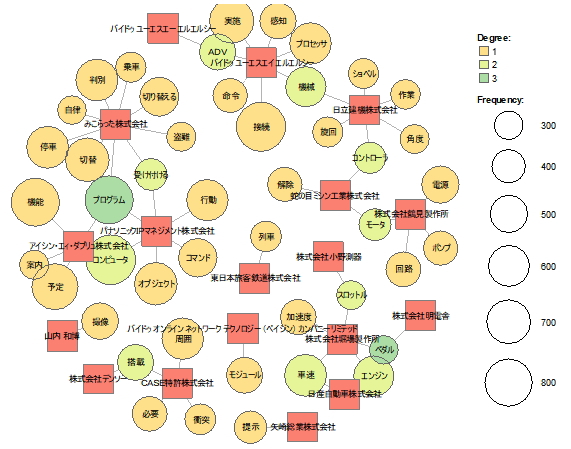
語と語の関係性を分析するということは、特許情報であれば、一つの技術要素と他の技術要素の関係性を見出したり、特定の課題に結び付いた解決手段や、出願人と技術要素の結びつきを発見することができます。対応分析、階層的クラスター分析、多次元尺度構成法、共起ネットワーク等を用いることができます。
内容が似た文書の群を探す
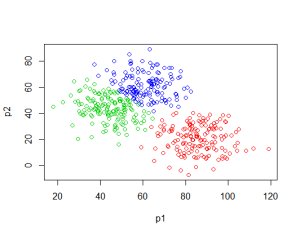
内容が似た文書の群を探すということは、ある関心のある技術分野の特許情報であれば、その技術分野の体系を見出すことができます。spectral clustering、dbscan、k-means法等による文書クラスター分析等を用いることができます。尚、クラスター分析による視覚効果としてのマップ表現をしているものは少なく、前者との違いがある点に注意が必要です。類似文書を見つける手法は、ベイズ圧縮やBERT等の事前学習済み言語モデルを用いた類似文書検索、特許分野でも最近注目されている自動分類と関係しています。これ等を応用することで、例えば、SDIに取り入れたり、遡及調査のノイズリダクションをある程度、自動化することができます。
参考 ワードの頻度マイニングだけでも分析ができる
参考 教師データによる自動分類を特許マップの利点(理解しやすい全体俯瞰)に応用する
弊社では、特許データをマイニングした結果を提供する「パテントランドケープ」サービスを提供しています。



