

データ処理サービス
特許マップ作成におけるデータ処理の必要性
データベース検索→マップ出力という単純なフローであれば、あまりデータ処理は必要ありません。しかし、より緻密な特許マップを作成するためには、データ加工が必要となります。以下は、どのような場面で、どのようなデータ処理が必要かを記載します。
(1)出願人・出願人グループの名寄せ
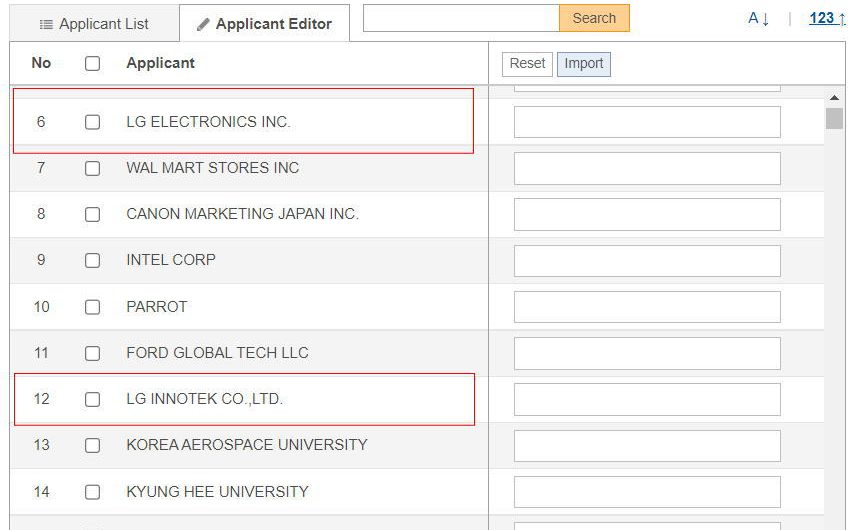
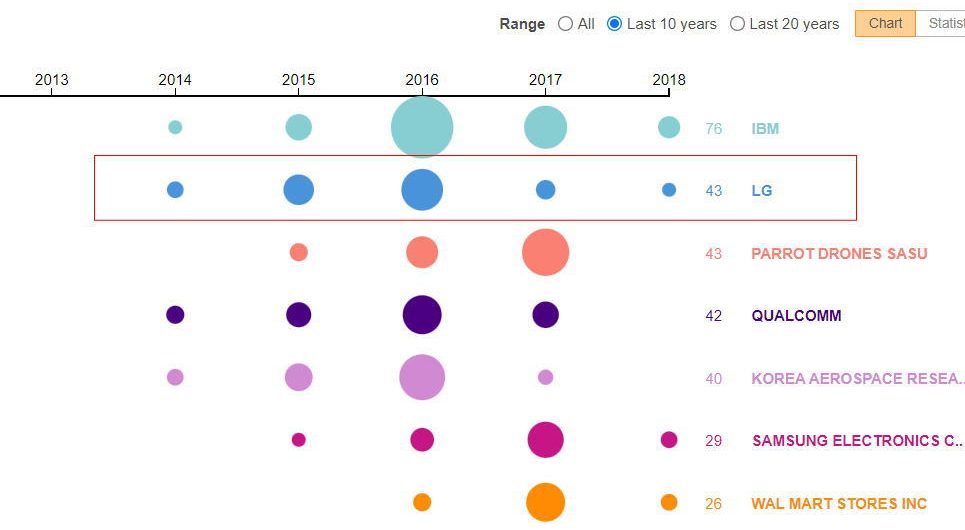
社名変更や譲渡等により、同一である出願人の表記が異なる場合は、それを同一の出願人であるとして、データ処理をする必要があります。特に海外の特許データの場合には、同一出願人であるにもかかわらず、英文表記が異なるものが多くあります。これらをバラバラに集計すると、よくわからない統計となります。また、競合分析においては、同一とみなしても良い出願人はまとめるほうが参入障壁としての実態を表しますので、その様な加工が必要になります。左の図は、特許検索システム上にそのような名寄せ機能がある場合の例です。6番目と12番目が同一であると見なし、右側のボックスに同一の表記を入力してまとめます。この事例では、上位6番目と12番目を一つにまとめると、上位2番目の企業になりました。このように出願人の名寄せ処理は、観察結果に大きな影響を与えるデータ処理の一つです。
処理が複雑になる場合(例えば、代表者での出願、発明者での出願を全て同一の企業としてまとめたい、中国の大学をひとつにまとめたい等で、観察する項目が出願人以外の項目が良い場合)は、商用データベースのUIでは十分に対応できなくなります。この場合は、テスクトップツール等で加工したほうが早く処理できます。
(2)要素技術の定義~シソーラスの統一など
特許マップでは、主に読み込みや形態素ワードを使用した特許マップの作成において、下記のような言葉の処理が必要です。
a) 代表化
集計を可能とするためには、記載さている内容から何を最も言わんとしているかを代表化する必要があります。しばしばこの作業は混乱します。その言葉の定義による代表化が必要です。
例) 「指サックの表面にブラシを形成」を「形態」を属性として捉え、そこに「指ブラシ」として記録したり、「ブラシ台」という属性として捉え、そこに「指型」として記録する作業など。
b) シソーラスの統一、グループ化
何について記載さているか、という視点で同じ概念として見做すか、区別するか。上位概念の言葉を選んでまとめるか、下位概念として区別するかを判断して修正していきます。
例) 「ぬいぐるみ」「人形」「玩具」を、「人形(ぬいぐるみ)」「玩具」とするか、全て「玩具」とするかなど。
c) 本質化
「黒」と「白」という色彩の要素があった場合、色彩の種類としてそのままクラスタリングするのではなく、「光吸収性」と「光反射性」として捉える事に意義がある場合があります。これらは、分析対象とするテーマや目的によって最適な技術的ワードに置き換えて判断する必要があります。
例) “基板の集積効率を上げるためにバンプを省略して接合し軽量化する”は、「集積効率」か、水平方向の解決技術とまとめて「容積縮小」とするか、ノートPCがテーマで「軽量化」とするか、あるいはコスト削減テーマで「省略」か良いのか?
(3)特許データのマージ
検索コマンド、言語、出力等の相違からデータの精度を上げるために、複数のデータベースを使用する場合があります。また公報単位データをファミリー化する場合、その逆の場合など、番号ルールやIT技術の障壁で労力がかかる場合があります。弊社では、日常的にこれらの処理を行っています。



